背景
此前接手了单位的大数据项目,项目跑在了一个由14台Linux服务器组成的集群上,其中每一台都是一个高配物理机。数据采用了redis进行缓存和简单持久化,后端基于java和hadoop,数据存储采用了分布式的HDFS作为持续存储。
刚接手的时候,主要是遇到磁盘分配不合理,redis资源配置不当等问题,进行重新疏理和配置时,发现了一个巨大的坑——磁盘空间有限,并且可用空间已经低于10%。当初与此前负责的同事沟通,表明每个服务器都还有一个3.5T的空闲存储未加入存储池使用,当进入每个服务器察看,也确实存在该“漏网之鱼”。
增加DataNode的数据目录
既然是发现了问题,当然不能袖手旁观了。
检查了之前的文件系统,发现服务器的文件系统采用了LVM管理的xfs文件系统,这就方便了,直接把空闲的磁盘加入VG,然后扩充使用的卷不就行了。然而反过头来考虑下,这个项目刚上手,并且对于HDFS的在用卷进行扩充,心里还是没底,查找资料发现可以增加datanode的数据目录,这下豁然开朗了,直接新建一个卷,然后把新卷挂载成新的路径,添加成新的数据目录不就了事。
于是有样学样,按照之前的存储使用,fdisk外加mkfs一气呵成,为了以后的数据安全,并没有把磁盘划分到卷组里面,而是直接采用了独立磁盘的型式,然后格式化成同之前的文件系统一样的xfs,检查错误,挂载……似乎一切都那么顺理成章。进而创建目录结构,保持与之前的数据目录的大结构一致。于是就有了如下的结果。

发现的又一个坑
前面的一切折腾完了,回到集群看一看,似乎一切都很完美,可用空间直接提升到了60%还多,足够接下来一段时间的折腾了。顺带着执行了一下数据平衡,倒是很快就完成了,完结撒花?进而进入其中一个datanode察看,隐隐觉得有些不对了,因为数据目录的使用率并不平均,之前的数据目录可用空间10%左右,而新加的数据目录差不多100%可用,于是发现了事情并不是这么简单。

三个月过后的填坑
其实上面的图就是近段时间的情况了已经,也就是三个月之后。现在可见的disk1目录已经接近100%的使用率了,可用空间已经不足1G,而disk2目录经过了这一段时间的读写,单个节点的数据也已经存在了200G以上,但是CM中已经可以明显看到datanode的报错了,其中的几个节点因为disk1的持续高占用,已经无法正常工作了。那么问题就来了,HDFS的数据平衡,是针对datanode之间的数据重新分布,那么节点内的数据目录数据平衡,要怎么实现呢?搜索了一下相关的文档,在hadoop文档库中,还真的找到了对应的工具,那就是HDFS Disk Balancer,官方对该工具的描述是
Diskbalancer is a command line tool that distributes data evenly on all disks of a datanode. This tool is different from Balancer which takes care of cluster-wide data balancing. Data can have uneven spread between disks on a node due to several reasons. This can happen due to large amount of writes and deletes or due to a disk replacement. This tool operates against a given datanode and moves blocks from one disk to another.
“针对一个给定的datanode并且将数据块从一个磁盘移动到其它磁盘”,这不正是我要的功能么。但是也正如官方的说明,disk balancer 在集群中默认是不启用的,需要手动在 hdfs-site.xml 中添加 dfs.disk.balancer.enabled 并设置其值为 true 以开启。
对应CM中,进入集群的配置,发现并没有已知的配置值,通过筛选器找到hdfs-site.xml,在如下位置添加配置吧。
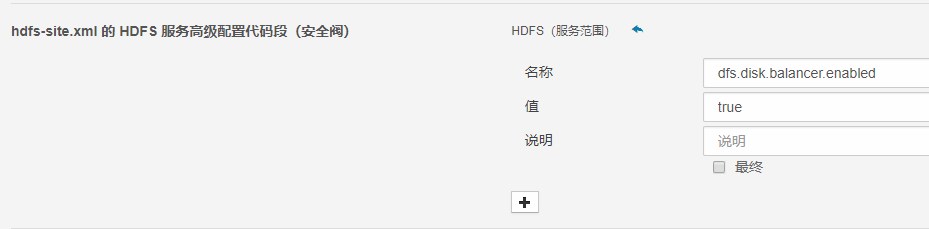
再对集群进行滚动重启,确保新的配置已经生效,再执行
hdfs diskbalancer -plan node1.mycluster.com
生成计划的json文件,然后
hdfs diskbalancer -execute /system/diskbalancer/nodename.plan.json
执行对应的计划文件,后台就会开启相应的数据平衡操作。
执行中可以通过
hdfs diskbalancer -query nodename.mycluster.com
查询单个节点的执行状态,或者
hdfs diskbalancer -cancel /system/diskbalancer/nodename.plan.json
取消正在执行的平衡操作。
不过根据实际情况,受限于磁盘的效率和网络速率,在进行大量数据的平衡操作时,消耗的时间还是较长的,不过就目前的情况看来,在进行数据目录的扩充时,进行diskbalance是非常有必要的。